 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Electrolaryngeal Speech Enhancement Through Speech-Text Representation Learning
Jun 01, 2026Objective: laryngectomees depend on an electromechanical device to generate electrolaryngeal (EL) speech. Compared with normal speech, EL speech suffers from severe distortion, limited phonetic variation, unnatural prosody, and temporal shifts, degrading naturalness and intelligibility. Although sequence-to-sequence (seq2seq) voice conversion (VC) based EL-speech-to-normal-speech conversion (EL2SP) is promising, substantial mismatches between EL and normal speech inevitably cause cumulative mapping errors that limit performance. To address this, we describe a novel representation learning framework integrating speech and text representations to improve mapping and reconstruction quality within a seq2seq VC model. Methods: our methodology comprises two main stages: 1) representation integration and learning, and 2) reconstruction training. A network capable of incorporating auxiliary text information is first constructed with pretrained modules to learn speech--text-based integrated representations. Then, an autoencoder-style reconstruction strategy finalizes EL2SP model to inherit these representations without increasing model complexity. We introduce three fusion strategies including middle-, input-, and hybrid-level fusion strategies that progressively enhance learning. Moreover, besides standard seq2seq VC objectives, an additional reconstruction loss on the integrated representation is introduced to refine representation transfer. Results: experiments under different EL2SP datasets consistently demonstrate that our methods, combined with data augmentations, outperform baselines relying solely on speech representations. Furthermore, progressive improvements with system design depth validate the effectiveness of our methods. Significance: the proposed methods provide an extensible and practical methodology for EL speech enhancement and assistive communication technologies.
* 15 pages, 7 figures. Accepted to IEEE TBME
Free energy Estimation on Any State Space
May 29, 2026Free energy estimation is a fundamental yet challenging problem, from physics to statistics. Classical approaches rely on thermodynamic transformations, ranging from direct estimation, quasistatic integration, to finite-time averaging. Recent work [He and Du et al., 2025] learns neural transports to significantly accelerate the efficiency in the finite-time regime. In this paper, we generalize this framework to arbitrary state spaces. Building on this view, we develop a generalized neural transport learning approach for efficient estimation. Experiments validate the effectiveness and efficiency of the proposed method beyond continuous settings, extending to discrete and multimodal spaces as well as autoregressive settings. Beyond free energy estimation, we establish algebraic identities and reveal a group-theoretic structure linking infinitesimal time reversal and generalized Doob's $h$-transforms, showing that their compositions form a generalized dihedral group.
Rare Event Analysis via Stochastic Optimal Control
Apr 14, 2026Rare events such as conformational changes in biomolecules, phase transitions, and chemical reactions are central to the behavior of many physical systems, yet they are extremely difficult to study computationally because unbiased simulations seldom produce them. Transition Path Theory (TPT) provides a rigorous statistical framework for analyzing such events: it characterizes the ensemble of reactive trajectories between two designated metastable states (reactant and product), and its central object--the committor function, which gives the probability that the system will next reach the product rather than the reactant--encodes all essential kinetic and thermodynamic information. We introduce a framework that casts committor estimation as a stochastic optimal control (SOC) problem. In this formulation the committor defines a feedback control--proportional to the gradient of its logarithm--that actively steers trajectories toward the reactive region, thereby enabling efficient sampling of reactive paths. To solve the resulting hitting-time control problem we develop two complementary objectives: a direct backpropagation loss and a principled off-policy Value Matching loss, for which we establish first-order optimality guarantees. We further address metastability, which can trap controlled trajectories in intermediate basins, by introducing an alternative sampling process that preserves the reactive current while lowering effective energy barriers. On benchmark systems, the framework yields markedly more accurate committor estimates, reaction rates, and equilibrium constants than existing methods.
Compression as Adaptation: Implicit Visual Representation with Diffusion Foundation Models
Mar 08, 2026Modern visual generative models acquire rich visual knowledge through large-scale training, yet existing visual representations (such as pixels, latents, or tokens) remain external to the model and cannot directly exploit this knowledge for compact storage or reuse. In this work, we introduce a new visual representation framework that encodes a signal as a function, which is parametrized by low-rank adaptations attached to a frozen visual generative model. Such implicit representations of visual signals, \textit{e.g.}, an 81-frame video, can further be hashed into a single compact vector, achieving strong perceptual video compression at extremely low bitrates. Beyond basic compression, the functional nature of this representation enables inference-time scaling and control, allowing additional refinement on the compression performance. More broadly, as the implicit representations directly act as a function of the generation process, this suggests a unified framework bridging visual compression and generation.
VisionCreator: A Native Visual-Generation Agentic Model with Understanding, Thinking, Planning and Creation
Mar 03, 2026Visual content creation tasks demand a nuanced understanding of design conventions and creative workflows-capabilities challenging for general models, while workflow-based agents lack specialized knowledge for autonomous creative planning. To overcome these challenges, we propose VisionCreator, a native visual-generation agentic model that unifies Understanding, Thinking, Planning, and Creation (UTPC) capabilities within an end-to-end learnable framework. Our work introduces four key contributions: (i) VisGenData-4k and its construction methodology using metacognition-based VisionAgent to generate high-quality creation trajectories with explicit UTPC structures; (ii) The VisionCreator agentic model, optimized through Progressive Specialization Training (PST) and Virtual Reinforcement Learning (VRL) within a high-fidelity simulated environment, enabling stable and efficient acquisition of UTPC capabilities for complex creation tasks; (iii) VisGenBench, a comprehensive benchmark featuring 1.2k test samples across diverse scenarios for standardized evaluation of multi-step visual creation capabilities; (iv) Remarkably, our VisionCreator-8B/32B models demonstrate superior performance over larger closed-source models across multiple evaluation dimensions. Overall, this work provides a foundation for future research in visual-generation agentic systems.
Assessing generative modeling approaches for free energy estimates in condensed matter
Dec 30, 2025The accurate estimation of free energy differences between two states is a long-standing challenge in molecular simulations. Traditional approaches generally rely on sampling multiple intermediate states to ensure sufficient overlap in phase space and are, consequently, computationally expensive. Several generative-model-based methods have recently addressed this challenge by learning a direct bridge between distributions, bypassing the need for intermediate states. However, it remains unclear which approaches provide the best trade-off between efficiency, accuracy, and scalability. In this work, we systematically review these methods and benchmark selected approaches with a focus on condensed-matter systems. In particular, we investigate the performance of discrete and continuous normalizing flows in the context of targeted free energy perturbation as well as FEAT (Free energy Estimators with Adaptive Transport) together with the escorted Jarzynski equality, using coarse-grained monatomic ice and Lennard-Jones solids as benchmark systems. We evaluate accuracy, data efficiency, computational cost, and scalability with system size. Our results provide a quantitative framework for selecting effective free energy estimation strategies in condensed-phase systems.
Pinching-Antenna System-Assisted Localization: A Stochastic Geometry Perspective
Nov 19, 2025



This paper proposes a novel localization framework underpinned by a pinching-antenna (PA) system, in which the target location is estimated using received signal strength (RSS) measurements obtained from downlink signals transmitted by the PAs. To develop a comprehensive analytical framework, we employ stochastic geometry to model the spatial distribution of the PAs, enabling tractable and insightful network-level performance analysis. Closed-form expressions for target localizability and the Cramer-Rao lower bound (CRLB) distribution are analytically derived, enabling the evaluation of the fundamental limits of PA-assisted localization systems without extensive simulations. Furthermore, the proposed framework provides practical guidance for selecting the optimal waveguide number to maximize localization performance. Numerical results also highlight the superiority of the PA-assisted approach over conventional fixed-antenna systems in terms of the CRLB.
Adversarial Learning-Based Radio Map Reconstruction for Fingerprinting Localization
Nov 18, 2025This letter presents a feature-guided adversarial framework, namely ComGAN, which is designed to reconstruct an incomplete fingerprint database by inferring missing received signal strength (RSS) values at unmeasured reference points (RPs). An auxiliary subnetwork is integrated into a conditional generative adversarial network (cGAN) to enable spatial feature learning. An optimization method is then developed to refine the RSS predictions by aggregating multiple prediction sets, achieving an improved localization performance. Experimental results demonstrate that the proposed scheme achieves a root mean squared error (RMSE) comparable to the ground-truth measurements while outperforming state-of-the-art reconstruction methods. When the reconstructed fingerprint is combined with measured data for training, the fingerprinting localization achieves accuracy comparable to models trained on fully measured datasets.
PARCO: Phoneme-Augmented Robust Contextual ASR via Contrastive Entity Disambiguation
Sep 04, 2025Automatic speech recognition (ASR) systems struggle with domain-specific named entities, especially homophones. Contextual ASR improves recognition but often fails to capture fine-grained phoneme variations due to limited entity diversity. Moreover, prior methods treat entities as independent tokens, leading to incomplete multi-token biasing. To address these issues, we propose Phoneme-Augmented Robust Contextual ASR via COntrastive entity disambiguation (PARCO), which integrates phoneme-aware encoding, contrastive entity disambiguation, entity-level supervision, and hierarchical entity filtering. These components enhance phonetic discrimination, ensure complete entity retrieval, and reduce false positives under uncertainty. Experiments show that PARCO achieves CER of 4.22% on Chinese AISHELL-1 and WER of 11.14% on English DATA2 under 1,000 distractors, significantly outperforming baselines. PARCO also demonstrates robust gains on out-of-domain datasets like THCHS-30 and LibriSpeech.
RNE: a plug-and-play framework for diffusion density estimation and inference-time control
Jun 06, 2025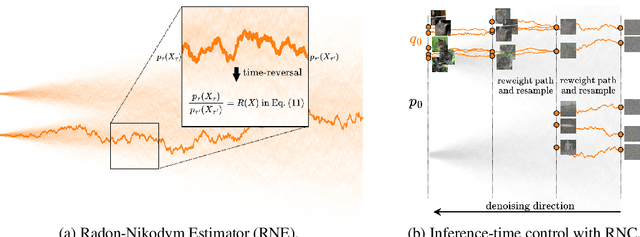
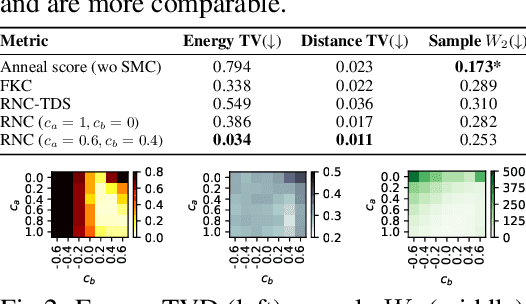

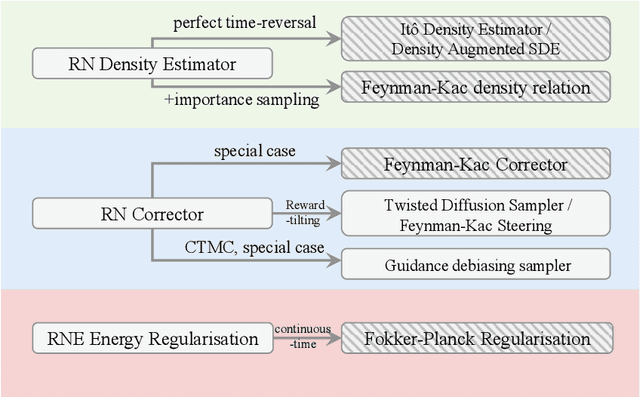
In this paper, we introduce the Radon-Nikodym Estimator (RNE), a flexible, plug-and-play framework for diffusion inference-time density estimation and control, based on the concept of the density ratio between path distributions. RNE connects and unifies a variety of existing density estimation and inference-time control methods under a single and intuitive perspective, stemming from basic variational inference and probabilistic principles therefore offering both theoretical clarity and practical versatility. Experiments demonstrate that RNE achieves promising performances in diffusion density estimation and inference-time control tasks, including annealing, composition of diffusion models, and reward-tilting.